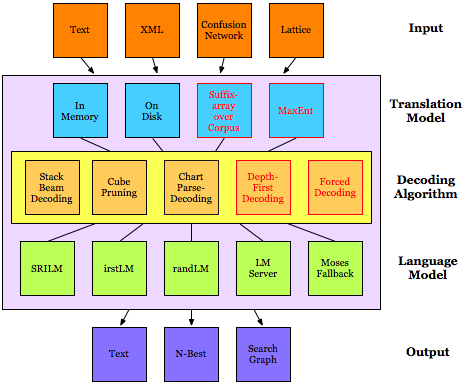
Moses
statistical
machine translation
system
Moses statistical machine translation system |
1. Moses

2. Getting Started
3. Tutorials
4. Training
- Overview
- Prepare training data
- Factored Training
- 1 Prepare data
- 2 Run GIZA
- 3 Align words
- 4 Lexical translation
- 5 Extract phrases
- 6 Score phrases
- 7 Reordering model
- 8 Generation model
- 9 Configuration file
 Language Models
Language Models
- Tuning
- Training Reference
- Decoder Reference
5. User Documentation
- Advanced Models
- Efficient Phrase and Rule Storage
- Search (Decoding)
- Unknown Words
- Hybrid Translation
- Moses as a Service
- Incremental Training
- Domain Adaptation
- Constrained Decoding
- Cache-based Models
- Sparse features
- Support Tools
- External Tools
- Web Translation
- Moses2
- Pipeline Creation Language
- Obsolete Features
6. Development
- Video
- Code Guide
- Code Style
- Factors
- Feature Functions
- Sparse Feature Functions
- Code Documentation
- Regression testing
7. Background