Moses2
Moses2 is a drop-in replacement for the Moses decoder. It is designed to be fast and scalable on multicore machines.
More information on Moses2 can be found in the AMTA paper
https://arxiv.org/abs/1610.04265
Content
Compiling
Moses2 is in the Moses' github repository, in the main ('master') branch, in the subdirectory
contrib/moses2
To create the executable, compile the Moses with the flag:
./bjam --with-xmlrpc-c=...
The following executable will be a created:
moses2
This is the command line version of Moses2, as well as the server. It should be used in the same way as Moses, eg.
bin/moses2 -f moses.ini -i in.txt -n-best-list nbest.txt 100
Notes
- Moses and Moses2 aren't exactly alike, there's some differences in pruning, stack configuration etc. The model scores are comparable though, so lower score in 1 indicates a search error.
- the phrase-based, cube-pruning model is the most the most optimised model. It is assumes this is the decoding algorithm most people will use in 'real-world' situations.
- It is also assumed that the phrase-table is pre-processed to only keep a small number (~100) of rule for each source phrase, rather than the 10,000 rules for the word 'the'.
- The speed emphasis is as much on multithreaded speed, not just with 1 thread
- Both phrase-based and hierarchical models are supported.
- Moses2 only implements a subset of the functionality of Moses. Unimplemented functionality are ignored, you won't get a warning, the decoder won't stop.
- Only a subset of feature functions, phrase-tables and language model implementations have been ported from Moses. However, if you are trying to use a feature function that hasn't been ported, the decoder will die.
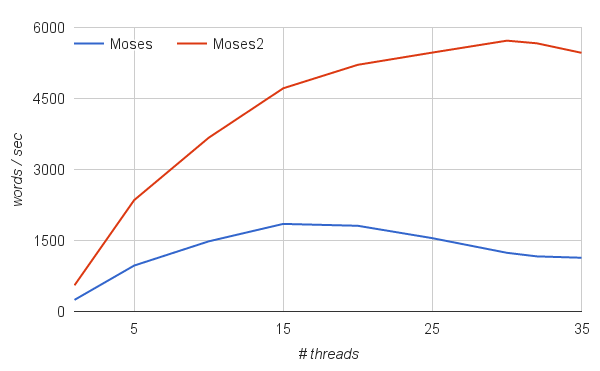
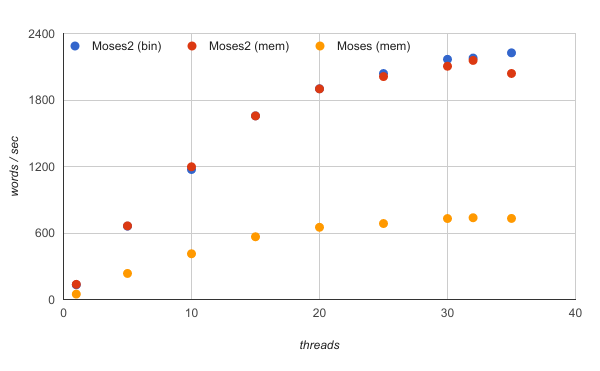
Performance
Cube-pruning algorithm
In testing with various models and test sets, phrase-based Moses2 is between 5-15 times faster than Moses for comparable configurations. Tests were done mostly with the cube-pruning algorithm running on modern (2016) servers with 32-cores, and taking advantage of all available cores.
All experiments were done with cube-pruning pop-limit of 400, using binary phrase-tables (probing pt for Moses2, compact pt for Moses).
For hierachical phrase-based models, the Moses2 implementation can be several hundred time faster than Moses:
| Word / sec | Moses | Moses2 |
|---|
| 1 thread | 0.99 | 102 |
| 32 threads | 2.28 | 567.21 |
Translation quality are comparable:
(Trained, tuned, and tested with UN data described in www.lrec-conf.org/proceedings/lrec2016/pdf/1195_Paper.pdf )
Standard phrase-based algorithm
Loading the phrase-table into memory and using the standard phrase-based decoding algorithm, the Moses decoder scales as well as the Moses2 decoder. However, Moses2 is consistently 3x faster.
Implemented functionality
Command line and moses.ini options available in Moses2 (as of June 2016)
- Standard phrase-based decoding -search-algorithm 0
- Cube-pruning -search-algorithm 1
- pop-limit -cube-pruning-pop-limit [NUM]
- lazy cube pruning -cube-pruning-lazy-scoring
- diversity -cube-pruning-diversity
- Stack size -stack [NUM]
- Distortion limit -distortion-limit [NUM]
- Maximum phrase length -max-phrase-length [NUM]
- Report segmentation -report-segmentation and - report-segmentation-enriched
- Output hypothesis score -output-hypo-score
- Number of decoding threads -threads [NUM]
- Multiple phrase-tables [mapping]
- Feature function weights [weight]
- n-best list -n-best-list [FILE] [NUM] [distinct]
- XML -xml-input [exclusive|inclusive|constraint|ignore|pass-through]
- Placeholder -placeholder-factor [NUM]
Options ONLY available in Moses2
Setting CPU affinity of each decoding thread
- -cpu-affinity-offset [NUM] and - cpu-affinity-increment [NUM]
Feature Functions
- UnknownWordPenalty
- WordPenalty
- PhrasePenalty
- ProbingPT
- PhraseDictionaryMemory
- PhraseDictionaryTransliteration
- Distortion
- KENLM
- OpSequenceModel
LexicalReordering
Supports only the in-memory and compact phrase datastructures from Moses. Also supports the lexicalized reordering model integrated into the phrase-table. To do this, provide the property-index argument rather than the path to a file, eg. change the line from:
LexicalReordering … path=reordering-table.msd-bidirectional-fe.0.5.0-0.gz
to
LexicalReordering … property-index=0
Additional Programs to Support Moses2
- addLexROtoPT – merge a phrase-table and a lexicalized reordering model. For example, given the following entry in the phrase-table and lexicalized reordering model:
PT: a b ||| c d ||| 1 2 3 4
Lex: a b ||| c d ||| 5 6 7 8 9 10
The resulting entry in the new phrase-table would be:
a b ||| c d ||| 1 2 3 4 ||| ||| ||| ||| {{LexRO 5 6 7 8 9 10}}
The original phrase-table must be a text file. The original lexicalized reordering model must have been binarized with the compact datastructure.
- CreateProbingPT – a fork of CreateProbingPT. Added extra options:
- -num-lex-scores [NUM] – The number of lexicalized reordering model scores contained in each rule
- --log-prob – probabilities are stored as natural log and floored scores so that they do not have to be processed during decoding.
- --max-cache-size [NUM] – Create a cache file of the NUM most frequent source phrases in the phrase-table. This is used to create a static cache for decoding.
- --scfg create phrase-table to be used in hierarchical decoding
- scripts/generic/binarize4moses2.perl
- a Script that combine the above programs. Create binary phrase table with integrated lexicalized reordering model.
- To use this script, Moses MUST be compiled with the flag --with-cmph. Also, the program in contrib/sigtest-filter MUST have been successfully compiled.


 Language Models
Language Models