Confusion Networks Decoding
Machine translation input currently takes the form of simple sequences of words. However, there are increasing demands to integrate machine translation technology in larger information processing systems with upstream natural language and/or speech processing tools (such as named entity recognizers, automatic speech recognizers, morphological analyzers, etc.). These upstream processes tend to generate multiple, erroneous hypotheses with varying confidence. Current MT systems are designed to process only one input hypothesis, making them vulnerable to errors in the input. We extend current MT decoding methods to process multiple, ambiguous hypotheses in the form of an input lattice. A lattice representation allows an MT system to arbitrate between multiple ambiguous hypotheses from upstream processing so that the best translation can be produced.
As lattice has usually a complex topology, an approximation of it, called confusion network, is used instead. The extraction of a confusion network from a lattice can be performed by means of a publicly available lattice-tool contained in the SRILM toolkit. See the SRILM manual pages for details and user guide.
Confusion Networks
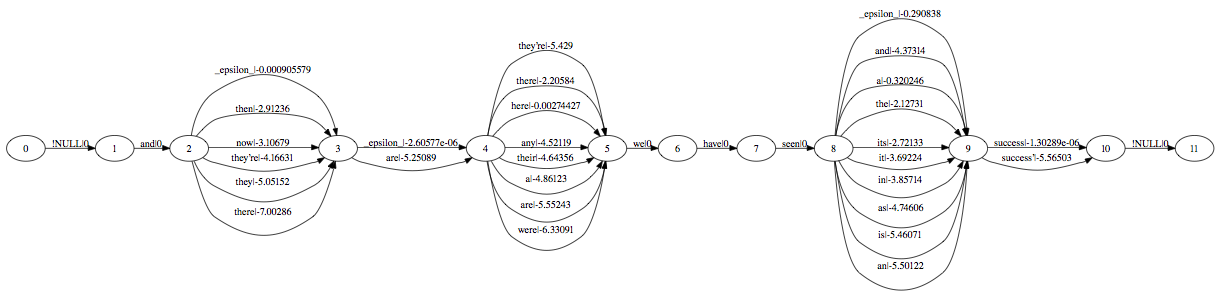
A Confusion Network (CN), also known as a sausage, is a weighted directed graph with the peculiarity that each path from the start node to the end node goes through all the other nodes.
Each edge is labeled with a word and a (posterior) probability.
The total probability of all edges between two consecutive nodes sum up to 1. Notice that this is not a strict constraint from the point of view of the decoder; any score can be provided. A path from the start node to the end node is scored by multiplying the scores of its edges. If the previous constrain is satisfied, the product represents the likelihood of the path, and the sum of the likelihood of all paths equals to 1.
Between any two consecutive nodes, one (at most) special word _eps_ can be inserted;
_eps_ words allows paths having different lengths.
Any path within a CN represents a realization of the CN.
Realizations of a CN can differ in terms of either sequence of words or total score. It is possible that two (or more) realizations have the same sequence of words, but different scores. Word lengths can also differ due to presence of the _eps_. This is a list of some realization of the previous CN.
aus der Zeitung score=0.252 length=3
Aus der Zeitung score=0.126 length=3
Zeitung score=0.021 length=1
Haus Zeitungs score=0.001 length=2
Notes
- A CN contains all paths of the lattice which is originated from.
- A CN can contain more paths than the lattice which is originated from (due
_eps_).
Representation of Confusion Network
Moses adopts the following computer-friendly representation for a CN.
Haus 0.1 aus 0.4 _eps_ 0.3 Aus 0.2
der 0.9 _eps_ 0.1
Zeitung 0.7 _eps_ 0.2 Zeitungs 0.1
where a line contains the alternative edges (words and probs) between two consecutive nodes.
In the factored representation, each line gives alternatives over the full factor space:
Haus|N 0.1 aus|PREP 0.4 Aus|N 0.4 _eps_|_eps_ 0.1
der|DET 0.1 der|PREP 0.8 _eps_|_eps_ 0.1
Zeitung|N 0.7 _eps_|_eps_ 0.2 Zeitungs|N 0.1
Notice that if you project the above CN on a single factor,
repetitions of factors must be merged and the respective probs
summed up. The corresponding word-projected CN is the one of the first
example, while the part-of-speech projected CN is:
N 0.5 PREP 0.4 _eps_ 0.1
DET 0.1 PREP 0.8 _eps_ 0.1
N 0.8 _eps_ 0.2


 Language Models
Language Models