Experiment Management System
Content
Introduction
The Experiment Management System (EMS), or Experiment.perl, for lack of a better name, makes it much easier to perform experiments with Moses.
There are many steps in running an experiment: the preparation of training data, building language and translation models, tuning, testing, scoring and analysis of the results. For most of these steps, a different tool needs to be invoked, so this easily becomes very messy.
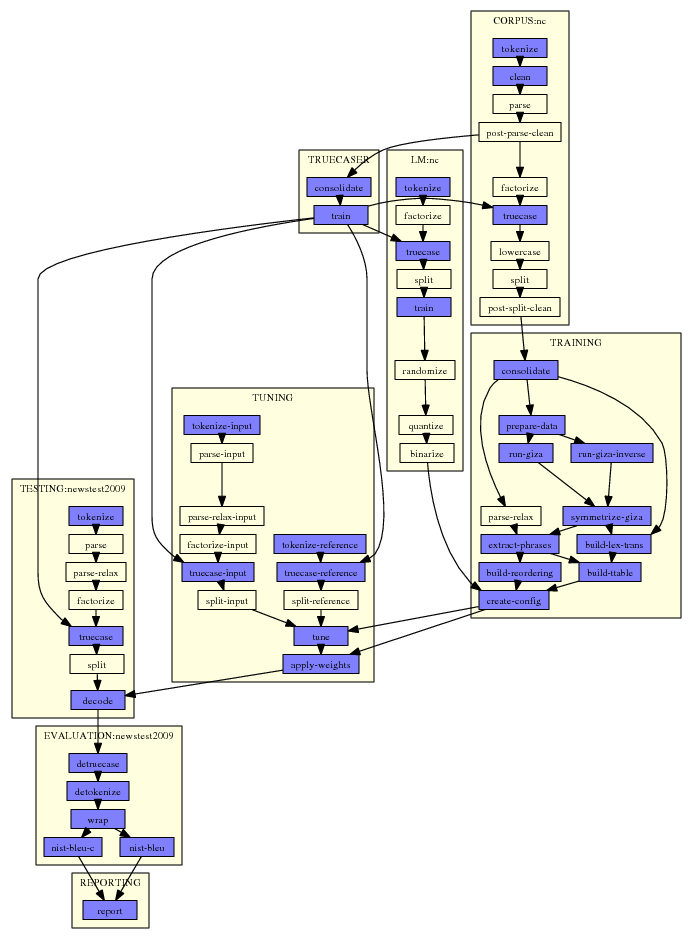
Here a typical example:
This graph was automatically generated by Experiment.perl. All that needed to be done was to specify one single configuration file that points to data files and settings for the experiment.
In the graph, each step is a small box. For each step, Experiment.perl builds a script file that gets either submitted to the cluster or run on the same machine. Note that some steps are quite involved, for instance tuning: On a cluster, the tuning script runs on the head node a submits jobs to the queue itself.
Experiment.perl makes it easy to run multiple experimental runs with different settings or data resources. It automatically detects which steps do not have to be executed again but instead which results from an earlier run can be re-used.
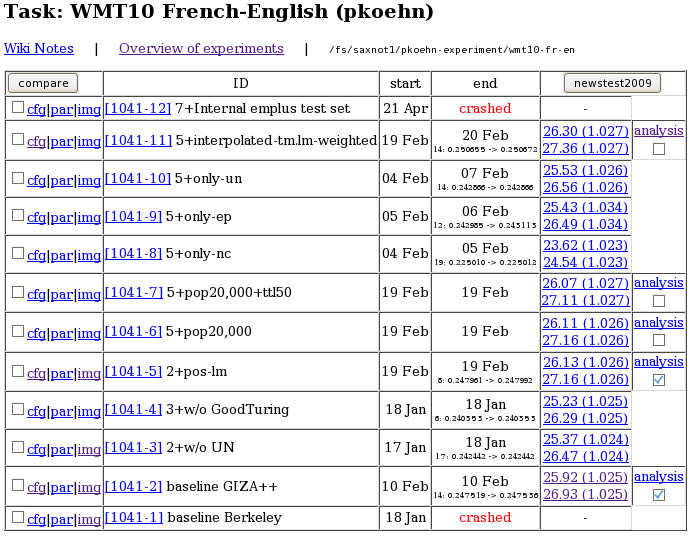
Experiment.perl also offers a web interface to the experimental runs for easy access and comparison of experimental results.
The web interface also offers some basic analysis of results, such as comparing the n-gram matches between two different experimental runs:
Requirements
In order to run properly, EMS will require:
Quick Start
Experiment.perl is extremely simple to use:
- Find
experiment.perl in scripts/ems
- Get a sample configuration file from someplace (for instance
scripts/ems/example/config.toy).
- Set up a working directory for your experiments for this task (
mkdir does it).
- Edit the following path settings in
config.toy
working-dir
data-dir
moses-script-dir
moses-src-dir
srilm-dir
decoder
- Run
experiment.perl -config config.toy from your experiment working directory.
- Marvel at the graphical plan of action.
- Run
experiment.perl -config config.toy -exec.
- Check the results of your experiment (in
evaluation/report.1)
Let us take a closer look at what just happened.
The configuration file config.toy consists of several sections. For instance there is a section for each language model corpus to be used. In our toy example, this section contains the following:
[LM:toy]
### raw corpus (untokenized)
#
raw-corpus = $toy-data/nc-5k.$output-extension
The setting raw-corpus species the location of the corpus. The definition uses the variables $toy-data and $output-extension, which are also settings defined elsewhere in the configuration file. These variables are resolved, leading to the file path ems/examples/data/nc-5k.en in your Moses scripts directory.
The authoritative definition of the steps and their interaction is in the file experiment.meta (in the same directory as experiment.perl: scripts/ems).
The logic of experiment.meta is that it wants to create a report at the end. To generate the report it needs to evaluation scores, to get these it needs decoding output, to get these it needs to run the decoder, to be able to run the decoder it needs a trained model, to train a model it needs data. This process of defining the agenda of steps to be executed is very similar to the Make utility in Unix.
We can find the following step definitions for the language model module in experiment.meta:
get-corpus
in: get-corpus-script
out: raw-corpus
default-name: lm/txt
template: IN > OUT
tokenize
in: raw-corpus
out: tokenized-corpus
default-name: lm/tok
pass-unless: output-tokenizer
template: $output-tokenizer < IN > OUT
parallelizable: yes
The tokenization step tokenize requires raw-corpus as input. In our case, we specified the setting in the configuration file. We could have also specified an already tokenized corpus with tokenized-corpus. This would allow us to skip the tokenization step. Or, to give another example, we could have not specified raw-corpus, but rather specify a script that generates the corpus with the setting get-corpus-script. This would have triggered the creation of the step get-corpus.
The steps are linked with the definition of their input in and output out. Each step has also a default name for the output (efault-name) and other settings.
The tokenization step has as default name lm/tok. Let us look at the directory lm to see which files it contains:
% ls -tr lm/*
lm/toy.tok.1
lm/toy.truecased.1
lm/toy.lm.1
We find the output of the tokenization step in the file lm/toy.tok.1. The toy was added from the name definition of the language model (see [LM:toy] in config.toy). The 1 was added, because this is the first experimental run.
The directory steps contains the script that executes each step, its STDERR and STDOUT output, and meta-information. For instance:
% ls steps/1/LM_toy_tokenize.1* | cat
steps/1/LM_toy_tokenize.1
steps/1/LM_toy_tokenize.1.DONE
steps/1/LM_toy_tokenize.1.INFO
steps/1/LM_toy_tokenize.1.STDERR
steps/1/LM_toy_tokenize.1.STDERR.digest
steps/1/LM_toy_tokenize.1.STDOUT
The file steps/2/LM_toy_tokenize.2 is the script that is run to execute the step. The file with the extension DONE is created when the step is finished - this communicates to the scheduler that subsequent steps can be executed. The file with the extension INFO contains meta-information - essential the settings and dependencies of the step. This file is checked to detect if a step can be re-used in new experimental runs.
In case that the step crashed, we expect some indication of a fault in STDERR (for instance the words core dumped or killed). This file is checked to see if the step was executed successfully, so subsequent steps can be scheduled or the step can be re-used in new experiments. Since the STDERR file may be very large (some steps create megabytes of such output), a digested version is created in STDERR.digest. If the step was successful, it is empty. Otherwise it contains the error pattern that triggered the failure detection.
Let us now take a closer look at re-use. If we run the experiment again but change some of the settings, say, the order of the language model, then there is no need to re-run the tokenization.
Here is the definition of the language model training step in experiment.meta:
train
in: split-corpus
out: lm
default-name: lm/lm
ignore-if: rlm-training
rerun-on-change: lm-training order settings
template: $lm-training -order $order $settings -text IN -lm OUT
error: cannot execute binary file
The mention of order in the list behind rerun-on-change informs experiment.perl that this step does need to be re-run, if the order of the language model changes. Since none of the settings in the chain of steps leading up to the training have been changed, the step can be re-used.
Try changing the language model order (order = 5 in config.toy), run experiment.perl again (experiment.perl -config config.toy) in the working directory, and you will see the new language model in the directory lm:
% ls -tr lm/*
lm/toy.tok.1
lm/toy.truecased.1
lm/toy.lm.1
lm/toy.lm.2
More Examples
The example directory contains some additional examples.
These require the training and tuning data released for the Shared Translation Task for WMT 2010.
Create a working directory, and change into it. Then execute the following steps:
mkdir data
cd data
wget http://www.statmt.org/wmt10/training-parallel.tgz
tar xzf training-parallel.tgz
wget http://www.statmt.org/wmt10/dev.tgz
tar xzf dev.tgz
cd ..
The examples using these corpora are
config.basic - a basic phrase based model,
config.factored - a factored phrase based model,
config.hierarchical - a hierarchical phrase based model, and
config.syntax - a target syntax model.
In all these example configuration files, most corpora are commented out. This is done by adding the word IGNORE at the end of a corpus definition (also for the language models). This allows you to run a basic experiment with just the News Commentary corpus which finished relatively quickly.
Remove the IGNORE to include more training data. You may run into memory and disk space problems when using some of the larger corpora (especially the news language model), depending on your computing infrastructure.
If you decide to use multiple corpora for the language model, you may also want to try out interpolating the individual language models (instead of using them as separate feature functions). For this, you need to comment out the IGNORE next to the [INTERPOLATED-LM] section.
You may also specify different language pairs by changing the input-extension, output-extension, and pair-extension settings.
Finally, you can run all the experiments with the different given configuration files and the data variations in the same working directory. The experimental management system figures out automatically which processing steps do not need to repeated because they can be re-used from prior experimental runs.
Phrase Model
Phrase models are, compared to the following examples, the simplest models to be trained with Moses and the fastest models to run. You may prefer these models over the more sophisticated models whose added complexity may not justify the small (if any) gains.
The example config.basic is similar to the toy example, except for a larger training and test corpora. Also, the tuning stage is not skipped. Thus, even with most of the corpora commented out, the entire experimental run will likely take a day, with most time taken up by word alignment (TRAINING_run-giza and TRAINING_run-giza-inverse) and tuning (TUNING_tune).
Factored Phrase Model
Factored models allow for additional annotation at the word level which may be exploited in various models. The example in config.factored uses part-of-speech tags on the English target side.
Annotation with part-of-speech tags is done with MXPOST, which needs to be installed first. Please read the installation instructions. After this, you can run experiment.perl with the configuration file config.factored.
If you compare the factored example config.factored with the phrase-based example config.basic, you will notice the definition of the factors used:
### factored training: specify here which factors used
# if none specified, single factor training is assumed
# (one translation step, surface to surface)
#
input-factors = word
output-factors = word pos
alignment-factors = "word -> word"
translation-factors = "word -> word+pos"
reordering-factors = "word -> word"
#generation-factors =
decoding-steps = "t0"
the factor definition:
#################################################################
# FACTOR DEFINITION
[INPUT-FACTOR]
# also used for output factors
temp-dir = $working-dir/training/factor
[OUTPUT-FACTOR:pos]
### script that generates this factor
#
mxpost = /home/pkoehn/bin/mxpost
factor-script = "$moses-script-dir/training/wrappers/make-factor-en-pos.mxpost.perl -mxpost $mxpost"
and the specification of a 7-gram language model over part of speech tags:
[LM:nc=pos]
factors = "pos"
order = 7
settings = "-interpolate -unk"
raw-corpus = $wmt10-data/training/news-commentary10.$pair-extension.$output-extension
This factored model using all the available corpora is identical to the Edinburgh submission to the WMT 2010 shared task for English-Spanish, Spanish-English, and English-German language pairs (the French language pairs also used the 109 corpus, the Czech language pairs did not use the POS language model, and German-English used additional pre-processing steps).
Hierarchical model
Hierarchical phrase models allow for rules with gaps. Since these are represented by non-terminals and such rules are best processed with a search algorithm that is similar to syntactic chart parsing, such models fall into the class of tree-based or grammar-based models. For more information, please check the Syntax Tutorial.
From the view of setting up hierarchical models with experiment.perl, very little has to be changed in comparison to the configuration file for phrase-based models:
% diff config.basic config.hierarchical
33c33
< decoder = $moses-src-dir/bin/moses
---
> decoder = $moses-src-dir/bin/moses_chart
36c36
< ttable-binarizer = $moses-src-dir/bin/processPhraseTable
---
> #ttable-binarizer = $moses-src-dir/bin/processPhraseTable
39c39
< #ttable-binarizer = "$moses-src-dir/bin/CreateOnDiskPt 1 1 5 100 2"
---
> ttable-binarizer = "$moses-src-dir/bin/CreateOnDiskPt 1 1 5 100 2"
280c280
< lexicalized-reordering = msd-bidirectional-fe
---
> #lexicalized-reordering = msd-bidirectional-fe
284c284
< #hierarchical-rule-set = true
---
> hierarchical-rule-set = true
413c413
< decoder-settings = "-search-algorithm 1 -cube-pruning-pop-limit 5000 -s 5000"
---
> #decoder-settings = ""
The changes are: a different decoder binary (by default compiled into bin/moses_chart) and ttable-binarizer are used. The decoder settings for phrasal cube pruning do not apply.
Also, hierarchical models do not allow for lexicalized reordering (their rules fulfill the same purpose), and the setting for hierarchical rule sets has to be turned on. The use of hierarchical rules is indicated with the setting hierarchical-rule-set.
Target syntax model
Syntax models imply the use of linguistic annotation for the non-terminals of hierarchical models. This requires running a syntactic parser.
In our example config.syntax, syntax is used only on the English target side. The syntactic constituents are labeled with Collins parser, which needs to be installed first. Please read the installation instructions.
Compared to the hierarchical model, very little has to be changed in the configuration file:
% diff config.hierarchical config.syntax
46a47,49
> # syntactic parsers
> collins = /home/pkoehn/bin/COLLINS-PARSER
> output-parser = "$moses-script-dir/training/wrappers/parse-en-collins.perl"
>
241c244
< #extract-settings = ""
---
> extract-settings = "--MinHoleSource 1 --NonTermConsecSource"
The parser needs to be specified, and the extraction settings may be adjusted. And you are ready to go.
Try a Few More Things
Stemmed Word Alignment
The factored translation model training makes it very easy to set up word alignment not based on the surface form of words, but any other property of a word. One relatively popular method is to use stemmed words for word alignment.
There are two reasons for this: For one, for morphologically rich languages, stemming overcomes data sparsity problems. Secondly, GIZA++ may have difficulties with very large vocabulary sizes, and stemming reduces the number of unique words.
To set up stemmed word alignment in experiment.perl, you need to define a stem as a factor:
[OUTPUT-FACTOR:stem4]
factor-script = "$moses-script-dir/training/wrappers/make-factor-stem.perl 4"
[INPUT-FACTOR:stem4]
factor-script = "$moses-script-dir/training/wrappers/make-factor-stem.perl 4"
and indicate the use of this factor in the TRAINING section:
input-factors = word stem4
output-factors = word stem4
alignment-factors = "stem4 -> stem4"
translation-factors = "word -> word"
reordering-factors = "word -> word"
#generation-factors =
decoding-steps = "t0"
Using Multi-Threaded GIZA++
GIZA++ is one of the slowest steps in the training pipeline. Qin Gao implemented a multi-threaded version of GIZA++, called MGIZA, which speeds up word alignment on multi-core machines.
To use MGIZA, you will first need to install it.
To use it, you simply need to add some training options in the section TRAINING:
### general options
#
training-options = "-mgiza -mgiza-cpus 8"
Using Berkeley Aligner
The Berkeley Aligner is a alternative to GIZA++ for word alignment. You may (or may not) get better results using this tool.
To use the Berkeley Aligner, you will first need to install it.
The example configuration file already has a section for the parameters for the tool. You need to un-comment them and adjust berkeley-jar to your installation. You should comment out alignment-symmetrization-method, since this is a GIZA++ setting.
### symmetrization method to obtain word alignments from giza output
# (commonly used: grow-diag-final-and)
#
#alignment-symmetrization-method = grow-diag-final-and
### use of berkeley aligner for word alignment
#
use-berkeley = true
alignment-symmetrization-method = berkeley
berkeley-train = $moses-script-dir/ems/support/berkeley-train.sh
berkeley-process = $moses-script-dir/ems/support/berkeley-process.sh
berkeley-jar = /your/path/to/berkeleyaligner-2.1/berkeleyaligner.jar
berkeley-java-options = "-server -mx30000m -ea"
berkeley-training-options = "-Main.iters 5 5 -EMWordAligner.numThreads 8"
berkeley-process-options = "-EMWordAligner.numThreads 8"
berkeley-posterior = 0.5
The Berkeley Aligner proceeds in two step: a training step to learn the alignment model from the data and a processing step to find the best alignment for the training data. This step has the parameter berkeley-posterior to adjust a bias towards more or less alignment points. You can try different runs with different values for this parameter. Experiment.perl will not re-run the training step, just the processing step.
Using Dyer's Fast Align
Another alternative to GIZA++ is fast_align from Dyer et al.. It runs much faster, and may even give better results, especially for language pairs without much large-scale reordering.
To use Fast Align, you will first need to install it.
The example configuration file already has a example setting for the tool, using the recommended defaults. Just remove the comment marker @#@ before the setting:
### use of Chris Dyer's fast align for word alignment
#
fast-align-settings = "-d -o -v"
Experiment.perl assumes that you copied the binary into the usual external bin dir (setting external-bin-dir) where GIZA++ and other external binaries are located.
IRST Language Model
The provided examples use the SRI language model during decoding. When you want to use the IRSTLM instead, an additional processing step is required: the language model has to converted into a binary format.
This part of the LM section defines the use of IRSTLM:
### script to use for binary table format for irstlm
# (default: no binarization)
#
#lm-binarizer = $moses-src-dir/irstlm/bin/compile-lm
### script to create quantized language model format (irstlm)
# (default: no quantization)
#
#lm-quantizer = $moses-src-dir/irstlm/bin/quantize-lm
If you un-comment lm-binarizer, IRSTLM will be used. If you comment out in addition lm-quantizer, the language model will be compressed into a more compact representation. Note that the values above assume that you installed the IRSTLM toolkit in the directory $moses-src-dir/irstlm.
Randomized Language Model
Randomized language models allow a much more compact (but lossy) representation. Being able to use much larger corpora for the language model may be beneficial over the small chance of making mistakes.
First of all, you need to install the RandLM toolkit.
There are two different ways to train a randomized language model. One is to train it from scratch. The other way is to convert a SRI language model into randomized representation.
Training from scratch: Find the following section in the example configuration files and un-comment the rlm-training setting. Note that the section below assumes that you installed the randomized language model toolkit in the directory $moses-src-dir/randlm.
### tool to be used for training randomized language model from scratch
# (more commonly, a SRILM is trained)
#
rlm-training = "$moses-src-dir/randlm/bin/buildlm -falsepos 8 -values 8"
Converting SRI language model: Find the following section in the example configuration files and un-comment the lm-randomizer setting.
### script to use for converting into randomized table format
# (default: no randomization)
#
lm-randomizer = "$moses-src-dir/randlm/bin/buildlm -falsepos 8 -values 8"
You may want to try other values for falsepos and values. Please see the language model section on RandLM for some more information about these parameters.
You can also randomize a interpolated language model by specifying the lm-randomizer in the section INTERPOLATED-LM.
Compound Splitting
Compounding languages, such as German, allow the creation of long words such as Neuwortgenerierung (new word generation). This results in a lot of unknown words in any text, so splitting up these compounds is a common method when translating from such languages.
Moses offers a support tool that splits up words, if the geometric average of the frequency of its parts is higher than the frequency of a word. The method requires a model (the frequency statistics of words in a corpus), so there is a training and application step.
Such word splitting can be added to experiment.perl simply by specifying the splitter script in the GENERAL section:
input-splitter = $moses-script-dir/generic/compound-splitter.perl
Splitting words on the output side is currently not supported.
A Short Manual
The basic lay of the land is: experiment.perl breaks up the training, tuning, and evaluating of a statistical machine translation system into a number of steps, which are then scheduled to run in parallel or sequence depending on their inter-dependencies and available resources. The possible steps are defined in the file experiment.meta. An experiment is defined by a configuration file.
The main modules of running an experiment are:
CORPUS: preparing a parallel corpus,
INPUT-FACTOR and OUTPUT-FACTOR: commands to create factors,
TRAINING: training a translation model,
LM: training a language model,
INTERPOLATED-LM: interpolate language models,
SPLITTER: training a word splitting model,
RECASING: training a recaser,
TRUECASING: training a truecaser,
TUNING: running minumum error rate training to set component weights,
TESTING: translating and scoring a test set, and
REPORTING: compile all scores in one file.
Experiment.Meta
The actual steps, their dependencies and other salient information are to be found in the file experiment.meta. Think of experiment.meta as a "template" file.
Here the parts of the step description for CORPUS:get-corpus and CORPUS:tokenize:
get-corpus
in: get-corpus-script
out: raw-stem
[...]
tokenize
in: raw-stem
out: tokenized-stem
[...]
Each step takes some input (in) and provides some output (out). This also establishes the dependencies between the steps. The step tokenize requires the input raw-stem. This is provided by the step get-corpus.
experiment.meta provides a generic template for steps and their interaction. For an actual experiment, a configuration file determines which steps need to be run. This configuration file is the one that is specified when invocing experiment.perl. It may contain for instance the following:
[CORPUS:europarl]
### raw corpus files (untokenized, but sentence aligned)
#
raw-stem = $europarl-v3/training/europarl-v3.fr-en
Here, the parallel corpus to be used is named europarl and it is provided in raw text format in the location $europarl-v3/training/europarl-v3.fr-en (the variable $europarl-v3 is defined elsewhere in the config file). The effect of this specification in the config file is that the step get-corpus does not need to be run, since its output is given as a file. More on the configuration file below in the next section.
Several types of information are specified in experiment.meta:
in and out: Established dependencies between steps; input may also be provided by files specified in the configuration.
default-name: Name of the file in which the output of the step will be stored.
template: Template for the command that is placed in the execution script for the step.
template-if: Potential command for the execution script. Only used, if the first parameter exists.
error: experiment.perl detects if a step failed by scanning STDERR for key words such as killed, error, died, not found, and so on. Additional key words and phrase are provided with this parameter.
not-error: Declares default error key words as not indicating failures.
pass-unless: Only if the given parameter is defined, this step is executed, otherwise the step is passed (illustrated by a yellow box in the graph).
ignore-unless: If the given parameter is defined, this step is not executed. This overrides requirements of downstream steps.
rerun-on-change: If similar experiments are run, the output of steps may be used, if input and parameter settings are the same. This specifies a number of parameters whose change disallows a re-use in different run.
parallelizable: When running on the cluster, this step may be parallelized (only if generic-parallelizer is set in the config file, the script can be found in $moses-script-dir/scripts/ems/support.
qsub-script: If running on a cluster, this step is run on the head node, and not submitted to the queue (because it submits jobs itself).
Here now the full definition of the step CONFIG:tokenize
tokenize
in: raw-stem
out: tokenized-stem
default-name: corpus/tok
pass-unless: input-tokenizer output-tokenizer
template-if: input-tokenizer IN.$input-extension OUT.$input-extension
template-if: output-tokenizer IN.$output-extension OUT.$output-extension
parallelizable: yes
The step takes raw-stem and produces tokenized-stem. It is parallizable with the generic parallelizer.
That output is stored in the file corpus/tok. Note that the actual file name also contains the corpus name, and the run number. Also, in this case, the parallel corpus is stored in two files, so file name may be something like corpus/europarl.tok.1.fr and corpus/europarl.tok.1.en.
The step is only executed, if either input-tokenizer or output-tokenizer are specified. The templates indicate how the command lines in the execution script for the steps look like.
Multiple Corpora, One Translation Model
We may use multiple parallel corpora for training a translation model or multiple monolingual corpora for training a language model. Each of these have their own instances of the CORPUS and LM module. There may be also multiple test sets in TESTING). However, there is only one translation model and hence only one instance of the TRAINING module.
The definitions in experiment.meta reflect the different nature of these modules. For instance CORPUS is flagged as multiple, while TRAINING is flagged as single.
When defining settings for the different modules, the singular module TRAINING has only one section, while this one general section and specific LM sections for each training corpus. In the specific section, the corpus is named, e.g. LM:europarl.
As you may imagine, the tracking of dependencies between steps of different types of modules and the consolidation of corpus-specific instances of modules is a bit complex. But most of that is hidden from the user of the Experimental Management System.
When looking up the parameter settings for a step, first the set-specific section (LM:europarl) is consulted. If there is no definition, then the module definition (LM) and finally the general definition (in section GENERAL) is consulted. In other words, local settings override global settings.
Defining Settings
The configuration file for experimental runs is a collection of parameter settings, one per line with empty lines and comment lines for better readability, organized in sections for each of the modules.
The syntax of setting definition is setting = value (note: spaces around the equal sign). If the value contains spaces, it must be placed into quotes (setting = "the value"), except when a vector of values is implied (only used when defining list of factors: output-factor = word pos.
Comments are indicated by a hash (#).
The start of sections is indicated by the section name in square brackets ([TRAINING] or [CORPUS:europarl]). If the word IGNORE is appended to a section definition, then the entire section is ignored.
Settings can be used as variables to define other settings:
working-dir = /home/pkoehn/experiment
wmt10-data = $working-dir/data
Variable names may be placed in curly brackets for clearer separation:
wmt10-data = ${working-dir}/data
Such variable references may also reach other modules:
[RECASING]
tokenized = $LM:europarl:tokenized-corpus
Finally, reference can be made to settings that are not defined in the configuration file, but are the product of the defined sequence of steps.
Say, in the above example, tokenized-corpus is not defined in the section LM:europarl, but instead raw-corpus. Then, the tokenized corpus is produced by the normal processing pipeline. Such an intermediate file can be used elsewhere:
[RECASING]
tokenized = [LM:europarl:tokenized-corpus]
Some error checking is done on the validity of the values. All values that seem to be file paths trigger the existence check for such files. A file with the prefix of the value must exist.
There are a lot of settings reflecting the many steps, and explaining these would require explaining the entire training, tuning, and testing pipeline. Please find the required documentation for step elsewhere around here. Every effort has been made to include verbose descriptions in the example configuration files, which should be taken as starting point.
Working with Experiment.Perl
You have to define an experiment in a configuration file and the Experiment Management System figures out which steps need to be run and schedules them either as jobs on a cluster or runs them serially on a single machine.
Other options:
-no-graph: Supresses the display of the graph.
-continue RUN: Continues the experiment RUN, which crashed earlier. Make sure that crashed step and its output is deleted (see more below).
-delete-crashed RUN: Delete all step files and their output files for steps that have crashed in a particular RUN.
-delete-run RUN: Delete all step files and their output files for steps for a given RUN, unless these steps are used by other runs.
-delete-version RUN: Same as above.
-max-active: Specifies the number of steps that can be run in parallel when running on a single machine (default: 2, not used when run on cluster).
-sleep: Sets the number of seconds to be waited in the scheduler before the completion of tasks is checked (default: 2).
-ignore-time: Changes the re-use behavior. By default files cannot be re-used when their time stamp changed (typically a tool such as the tokenizer which was changed, thus requiring re-running all tokenization steps in new experiments). With this switch, files with changed time stamp can be re-used.
-meta: Allows the specification of a custom experiment.meta file, instead of using the one in the same directory as the experiment.perl script.
-final-step STEP: Do not run a complete experiment, but finish at the specified STEP.
-final-out OUT: Do not run a complete experiment, but finish when the specified output file OUT is created. These are the output file specifiers as used in experiment.meta.
-cluster: Indicates that the current machine is a cluster head node. Step files are submitted as jobs to the cluster.
-multicore: Indicates that the current machine is a multi-core machine. This allows for additional parallelization with the generic parallelizer setting.
The script may automatically detect if it is run on a compute cluster or a multi-core machine, if this is specified in the file experiment.machines, for instance:
cluster: townhill seville
multicore-8: tyr thor
multicore-16: loki
defines the machines townhill and seville as GridEngine cluster machines, tyr and thor as 8-core machines and loki as 16-core machines.
Typically, experiments are started with the command:
experiment.perl -config my-config -exec
Since experiments run for a long time, you may want to run this in the background and also set a nicer priority:
nice nohup -config my-config -exec >& OUT.[RUN] &
This keeps also a report (STDERR and STDOUT) on the execution in a file named, say, OUT.1, with the number corresponding to the run number.
The meta-information for the run is stored in the directory steps. Each run has a sub directory with its number (steps/1, steps/2, etc.). The sub directory steps/0 contains step specification when Experiment.perl is called without the -exec switch.
The sub directories for each run contain the step definitions, as well as their meta-information and output. The sub directories also contain a copy of the configuration file (e.g. steps/1/config.1), the agenda graph (e.g. steps/1/graph.1.{dot,ps,png}), a file containing all expanded parameter settings (e.g. steps/1/parameter.1), and an empty file that is touched every minute as long as the experiment is still running (e.g. steps/1/running.1).
Continuing Crashed Experiments
Steps may crash. No, steps will crash, be it because faulty settings, faulty tools, problems with the computing resources, willful interruption of an experiment, or an act of God.
The first thing to continue a crashed experiment is to detect the crashed step. This is shown either by the red node in the displayed graph or reported on the command line in the last lines before crashing; though this may not be pretty obvious, if parallel steps kept running after that. However, the automatic error detection is not perfect and a step may have failed upstream without detection causes failure further down the road.
You should have a understanding of what each step does. Then, by looking at its STDERR and STDOUT file, and the output files it should have produced, you can track down what went wrong.
Fix the problem, and delete all files associated with the failed step (e.g., rm steps/13/TUNING_tune.13*, rm -r tuning/tmp.1). To find what has been produced by the crashed step, you may need to consult where the output of this step is placed, by looking at experiment.meta.
You can automatically delete all crashed steps and their output files with
experiment.perl -delete-crashed 13 -exec
After removing the failed step and ensuring that the cause of the crash has been addressed, you can continue a crashed experimental run (e.g., run number 13) with:
experiment.perl -continue 13 -exec
You may want to check what will be run by excluding the -exec command at first. The graph indicates which steps will be re-used from the original crashed run.
If the mistake was a parameter setting, you can change that setting in the stored configuration file (e.g., steps/1/config.1). Take care, however, to delete all steps (and their subsequent steps) that would have been run differently with that setting.
If an experimental run crashed early, or you do not want to repeat it, it may be easier to delete the entire step directory (rm -r steps/13). Only do this with the latest experimental run (e.g., not when there is already a run 14), otherwise it may mess up the re-use of results.
You may also delete all output associated with a run with the command rm -r */*.13*. However this requires some care, so you may want to check first what you are deleting (ls */*.13).
Running a Partial Experiment
By default, experiment.perl will run a full experiment: model building, tuning and testing. You may only want to run parts of the pipeline, for instance building a model, but not tuning and testing. You can do this by specifying either a final step or a final outcome.
If you want to terminate at a specific step
experiment.perl -config my-config -final-step step-name -exec
where step-name is for instance TRAINING:create-config, LM:my-corpus:train, or TUNING:tune.
If you want to terminate once a particular output file is generated:
experiment.perl -config my-config -final-out out -exec
Examples for out are TRAINING:config, LM:my-corpus:lm, or TUNING:weight-config. In fact, these three examples are identical to the three examples above, it is just another way to specify the final point of the pipeline.
Technically, this works by not using REPORTING:report as the end point of the pipeline, but the specified step.
Removing a Run
If you want to remove all the step files and output files associated with a particular run, you can do this with, for instance:
experiment.perl -delete-run 13 -exec
If you run this without -exec you will see a list of files that would be deleted (but no files are actually deleted).
Steps that are used in other runs, and the output files that they produced are kept. Also, the step directory (e.g., steps/13 is not removed. You may remove this by hand, if there are no step files left.
Running on a Cluster
Experiment.perl works with Sun GridEngine clusters. The script needs to be run on the head node and jobs are scheduled on the nodes.
There are two ways to tell experiment.perl that the current machine is a cluster computer. One is by using the switch -cluster, or by adding the machine name into experiment.machines.
The configuration file has a section that allows for the setting of cluster-specific settings. The setting jobs is used to specify into how many jobs to split the decoding during tuning and testing. For more details on this, please see moses-parallel.pl.
All other settings specify switches that are passed along with each submission of a job via qsub:
qsub-memory: number of memory slots (-pe memory NUMBER),
qsub-hours: number of hours reserved for each job (-l h_rt=NUMBER:0:0),
qsub-project: name if the project for user accounting (-P PROJECT), and
qsub-settings: any other setting that is passed along verbatim.
Note that the general settings can be overriden in each module definition - you may want to have different settings for different steps.
If the setting generic-parallelizer is set (most often it is set to to the ems support script $moses-script-dir/ems/support/generic-parallelizer.perl), then a number of additional steps are parallelized. For instance, tokenization is performed by breaking up the corpus into as many parts as specified with jobs, jobs to process the parts are submitted in parallel to the cluster, and their output pieced together upon completion.
Be aware that there are many different ways to configure a GridEngine cluster. Not all the options described here may be available, and it my not work out of the box, due to your specific installation.
Running on a Multi-core Machine
Using a multi-core machine means first of all that more steps can be scheduled in parallel. There is also a generic parallelizer (generic-multicore-parallelizer.perl) that plays the same role as the generic parallelizer for clusters.
However, decoding is not broken up into several pieces. It is more sensible to use multi-threading in the decoder.
Web Interface
The introduction included some screen shots of the web interface to the Experimental Management System. You will need to have a running web server on a machine (LAMPP on Linux or MAMP on Mac does the trick) that has access to the file system where your working directory is stored.
Copy or link the web directory (in scripts/ems) on a web server. Make sure the web server user has the right write permissions on the web interface directory.
To add your experiments to this interface, add a line to the file /your/web/interface/dir/setup. The format of the file is explained in the file.
Analysis
You can include additional analysis for an experimental run into the web interface by specifying the setting analysis in its configuration file.
analysis = $moses-script-dir/ems/support/analysis.perl
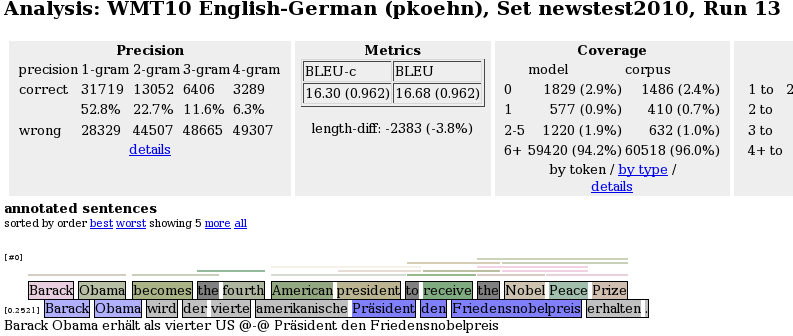
This currently reports n-gram precision and recall statistics and color-coded n-gram correctness markup for the output sentences, as in
The output is color-highlighted according to n-gram matches with the reference translation. The following colors are used:
- grey: word not in reference,
- light blue: word part of 1-gram match,
- blue: word part of 2-gram match,
- dark blue: word part of 3-gram match, and
- very dark blue: word part of 4-gram match.
Segmentation
The setting analyze-coverage include a coverage analysis: which words and phrases in the input occur in the training data or the translation table? This is reported in color coding and in a yellow report box when moving the mouse of the word or the phrase. Also, summary statistics for how many words occur how often are given, and a report on unknown or rare words is generated.
Coverage Analysis
The setting analyze-coverage include a coverage analysis: which words and phrases in the input occur in the training data or the translation table? This is reported in color coding and in a yellow report box when moving the mouse of the word or the phrase. Also, summary statistics for how many words occur how often are given, and a report on unknown or rare words is generated.
Bilingual Concordancer
To more closely inspect where input words and phrases occur in the training corpus, the analysis tool includes a bilingual concordancer. You turn it on by adding this line to the training section of your configuration file:
biconcor = $moses-bin-dir/biconcor
During training, a suffix array of the corpus is built in the model directory. The analysis web interface accesses these binary files to quickly scan for occurrences of source words and phrases in the training corpus. For this to work, you need to include the biconcor binary in the web root directory.
When you click on a word or phrase, the web page is augemented with a section that shows all (or frequent word, a sample of all) occurences of that phrase in the corpus, and how it was aligned:
Source occurrences (with context) are shown on the left half, the aligned target on the right.
In the main part, occurrences are grouped by different translations --- also shown bold in context. Unaligned boundary words are shown in blue. The extraction heuristic extracts additional rules for these cases, but these are not listed here for clarity.
At the end, source occurrences for which no rules could be extracted are shown. This may happen because the source words are not aligned to any target words. In this case, the tool shows alignments of the previous word (purple) and following word(olive), as well as some neighboring unaligned words (again, in blue). Another reason for failure to extract rules are misalignments, when the source phrase maps to a target span which contains words that also align to outside source words (violation of the coherence contraint). These misaligned words (in source and target) are shown in red.
Note by Dingyuan Wang - biconcor binary should be copied to the web interface directory.
Precision by coverage
To investigate further, if the correctness of the translation of input words depends on frequency in the corpus (and what the distribution of word frequency is), a report for precision by coverage can be turned on with the following settings:
report-precision-by-coverage = yes
precision-by-coverage-factor = pos
precision-by-coverage-base = $working-dir/evaluation/test.analysis.5
Only the first setting report-precision-by-coverage is needed for the report. The second setting precision-by-coverage-factor provides an additional breakdown for a specific input factor (in the example, the part-of-speech factor named pos). More on the precision-by-coverage-base below.
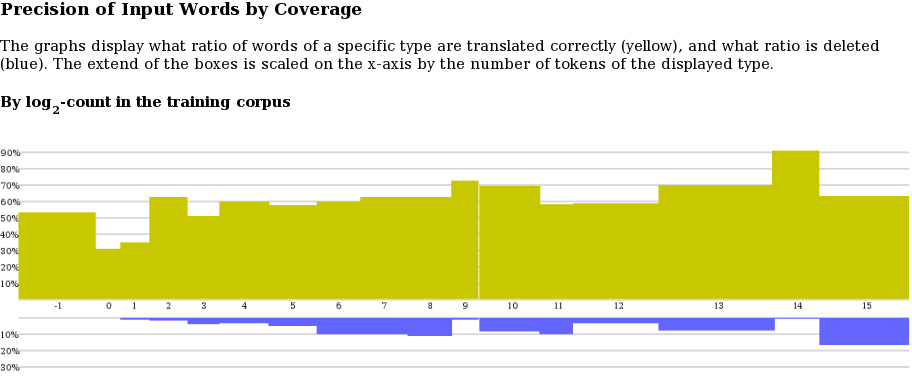
When clicking on "precision of input by coverage" on the main page, a precision by coverage graph is shown:
The log-coverage class is on the x-axis (-1 meaning unknown, 0 singletons, 1 words that occur twice, 2 words that occur 3-4 times, 3 words that occur 5-8 times, and so on). The scale of boxes for each class is determined by the ratio of words in the class in the test set. The precision of translations of words in a class is shown on the y-axis.
Translation of precision of input words cannot be determined in a clear cut word. Our determination relies on phrase alignment of the decoder, word alignment within phrases, and accounting for multiple occurrences of transled words in output and reference translations. Not that the precision metric does not penalize for dropping words, so this is shown in a second graph (in blue), below the precision graph.
If you click on the graph, you will see the graph in tabular form. Following additional links allows you to see breakdowns for the actual words, and even find the sentences in which they occur.
Finally, the precision-by-coverage-base setting. For comparison purposes, it may be useful to base the coverage statistics on the corpus of a previous run. For instance, if you add training data, does the translation quality of the words increase? Well, a word that occured 3 times in the small corpus, may now occur 10 times in the big corpus, hence the word is placed in a different class. To maintain the original classification of words into the log-coverage classes, you may use this setting to point to an earlier run.


 Language Models
Language Models