Announcements
| Please register here! |
📢 May 6, 2026 - Website released, and the task is announced!
| We are still updating the page. Please keep your eye on it! |
Overview 🧑🏫
We present the second shared task for Creole language machine translation, a continuation of last year’s task. We hope that this shared task may engage more researchers from Creole language-speaking communities, as well as those interested in Creole language technologies.
This shared task contains two categories of subtasks:
-
Task 1: Models for Creole language translation
-
Subtask 1A: Models for machine translation (MT) of Creole languages
-
Subtask 1B: Models for language identification (LID) of Creole languages
-
-
Task 2: Datasets for Creole language translation
-
Subtask 2A: Aligned bitexts for Creole language machine translation (MT)
-
Subtask 2B: Speech datasets for Creole languages
-
Subtask 1A: MT models 🤖
We solicit MT systems that translate between any number of Creole languages and English or French. If a participant would like to create a system to translate between a Creole language and another language considered culturally relevant to the community in question, this may be arranged by contacting the task organizers.
The purpose of this subtask is to encourage creation of state-of-the-art Creole language MT systems. Hence, teams will be allowed to use data from any source, and any pre-trained models or LLMs EXCEPT for those expressly prohibited. (However we will require teams to report the percentage of test set segments that were contained in the training data they use; we will provide the software to compute this when the evaluation period begins.) We encourage teams to experiment LLM-based systems, as this is under-studied in the Creole language space.
PROVIDED RESOURCES
Baseline models: These will be provided shortly 🔜
-
The primary baseline model will be this newly trained Gemma model
-
If compute constraints prohibit use of the primary baseline, we recommend use of kreyol-mt-pubtrain as a secondary baseline
-
🚨 NOTE: these models are off-limits: kreyol-mt, kreyol-mt-scratch, CreoleM2M
Provided train and dev data:
-
The
trainanddevsplits from Kreyòl-MT Data -
🚨 NOTE: the
testset is off limits!
Eval data: These will be provided shortly 🔜
RESTRICTIONS
🚨 Prohibited resources 🚨
-
You may not use these pre-trained models in ANY capacity
-
You may not use these data in ANY capacity:
-
The
testsplit from the Kreyòl-MT Data
-
ACCEPTABLE LANGUAGE PAIRS
We will accept submissions for any of the Creole languages supported by Kreyòl-MT or CreoleM2M (though these models may not be used); with translation into/out of English and/or French permitted for languages supported by Kreyòl-MT, and translation into/out of English permitted for the languages supported by CreoleM2M only. We will furnish test sets for each of these languages pairs (at least, all those for which we receive at least one submission).
We will also accept submissions for Creole languages yet supported by neither Kreyòl-MT nor CreoleM2M. In this case, we will require that participants submit an eval set meeting the requirements detailed in Subtask 2A as part of their submission, since we won’t have an eval set of our own for the language pair. (This is the same as the requirement for translation directions into or out of a language other than English and French, as mentioned earlier.)
Subtask 1B: LID models
The existing datasets for Creole language MT are, for the most part, manually curated and organized. A common way to expand existing resources is through web-crawling. However, web-crawling multilingual data requires high-quality language identification (LID). We hence challenge participants to develop LID systems for Creole languages from existing data, which will be evaluated on private evaluation sets of an unknown genre.
In line with recent critical work in LID, we aim to explore the applicability of multilabel classification and metadata-aware LID in the context of contact languages with high levels of overlap. This will likely take the form of dealing with texts where several answers are plausible, but some form(s) of metadata (e.g. title, URL, location, or another part of the document) help(s) to disambiguate. More details will be provided at a later date.
As several previous works have demonstrated community interest in LID for English-, French, Portuguese-, and Spanish-lexifier Creoles and Pidgins, we plan to focus on these groups for the first iteration for the LID task. We envision having both targeted evaluation for each lexifier group, as well as an across-the-board evaluation. Should a participating team express specific interest in another lexical grouping, we will try to accommodate this where feasible.
For the baseline model, we will use GlotLID (Kargaran et al., 2023) due to its broad coverage. As a starting point, participants can use the publicly available fastText repository (fasttext.cc/docs/en/language-identification.html) to create a similar model for their language groups. However, we encourage participants to explore a wide variety of potential solutions.
In addition to classification metrics (F1 and FPR), we will also measure runtime.
Subtask 2A: MT Data 📚
We solicit contributions to Creole language MT training and evaluation sets, in bitext formats with translations into any other language (though stronger submissions will be able to justify why the other language is relevant for the Creole language-speaking community).
DATA REQUIREMENTS
-
Participants must show that 100% of translations were either translated or post-edited by competent native or proficient speakers of the source and target languages. (Stronger quality assurances, such as only native speakers or translation instead of post-editing, will lead to stronger submissions.)
-
We require a data card with each submitted data set.
-
Participants must be able to show that one of the languages in each submitted bitext is considered a Creole language, by citing adequate academic sources or other sufficiently convincing means.
-
If submitting training data, it is strongly encouraged that participants use it to develop an MT system and evaluate this system on a test set (either a test set of their own creation, which must be submitted along with the training data, or a previously published test set). It is encouraged that participants show significant (p < 0.05) improvements in chrF++ over the previous state-of-the-art open-source MT system for the language pair. (To do this they must identify the previous SOTA model and make a compelling case for why it would be considered SOTA.) We will provide software to assist with meeting this requirement when the evaluation period begins. If participants are not able to meet this requirement, they must provide other convincing evidence of the utility of their training set.
-
If submitting a test set, participants must use it to evaluate performance of an MT model and provide compelling evidence that the model’s performance on the test set aligns with conventional wisdom regarding the model’s performance in the translation direction.
Please direct any questions about these requirements to the task organizers.
SEED DATASET
We provide a seed dataset for translation into a test set for teams interested.
It is simply the FLORES-200 English devtest set. Teams may choose to translate all 1k
segments into their Creole language of choice, or to opt for a subset of them (so long as
they can make a convincing case that the dataset size is sufficient for a high quality
test set). Naturally if teams wish to also translate the FLORES-200 dev sets as well,
they are welome to do so.
Here are instructions to download the seed dataset:
from datasets import load_dataset
flores_code = "eng_Latn"
devtest_set = load_dataset(
"facebook/flores",
flores_code,
split="devtest",
trust_remote_code=True
) # len ~= 1000Subtask 2B: Speech data 💬
Speech applications are broadly needed for Creole languages. However Creole speech technologies is still a nascient field with few resources. We hence challenge interested participants to submit datasets with Creole language speech data. Each dataset must:
-
Contain segments not exceeding 60 seconds of speech in a Creole language
-
Contain textual transcriptions or translations of such segments
-
Be large enough to train a speech recognition system to perform better than 90% WER on held out data, or a speech translation system to perform better than 15.0 chrF++ on held out data
More details to come
Task Information 📢
System / dataset report: For all subtasks, we’ll ask task participants to submit a 4-8 page paper to detail and publicize their contributions.
REGISTRATION
If you plan to participate, please register for the shared task using this form.
IMPORTANT DATES
May 6, 2026 |
Website released, and the task is announced! |
May 6, 2026 |
Team registration open |
June 7 June 15, 2026 |
All baseline models and provided training data released |
July 11, 2026 |
Registration closes |
June 18 July 22, 2026 |
Test sets released (evaluation cycle begins) |
June 25 July 29, 2026 |
System submissions due (evaluation cycle ends) |
August, 2026, in-line with WMT26 |
System paper submission |
November, 2026 |
Under EMNLP conference |
SYSTEM SUBMISSION
This is relevant for teams participating in subtask 1A or 1B.
Each team may submit up to three (3) systems for each language or
language pair. These are to be denoted primary, contrastive1, and
contrastive2 (in that order of priority in case only one or two systems
are submitted). Typically teams will designate whichever system they are most
confident of as primary.
System submission for subtask 1A
At the start of the evaluation cycle, we will send each participating team the source-side texts for the eval set of each language pair they have registered for. The team will then use their system(s) to translate the source lines, which they must send to creolemtsharedtask@gmail.com by the end of the evaluation cycle. Each submission file must have exactly the same number of lines as the source-side eval set provided. Each submission file should be named with the following format:
-
<team-name>.1a.<submission>.<source-language>-<target-language>.txt
Where <team-name> should be the team’s abbreviated name as indicated in the
registration form, <submission> should be either primary, contrastive1,
or contrastive2, <source-language> should be the three-letter ISO 639-3 code
of the source language in the translation pair, and <target-language> should be
the same for the target language.
For example, if my team were JHU, and I were submitting a primary system for
Haitian (hat) to English (eng), my submission file of translation
hypotheses would be named:
-
jhu.1a.primary.hat-eng.txt
System submission for subtask 1B
Similar to subtask 1A, we will send eval sets to participating teams at the start of the evaluation cycle. This will be in the form of a TXT file with text in an unspecified language on each line. The team’s submission should then be a TXT file with the same number of lines, where each line contains their system-determined language label for the corresponding eval set line. We will be in touch with teams individually regarding what labels to use for each language. Each submission file should have the following format:
-
<team-name>.1b.<submission>.txt
Where <team-name> should be the team’s abbreviated name as indicated in the
registration form, and <submission> should be either primary, contrastive1,
or contrastive2.
For example, if my team were JHU, and I were submitting a contrastive1 system, my submission file of LID hypotheses would be named:
-
jhu.1b.contrastive1.txt
PAPER SUBMISSION
in-line with WMT26
All deadlines are in AoE (Anywhere on Earth). Dates are specified with respect to EMNLP 2025.
ORGANIZERS
-
Nathaniel R. Robinson (Johns Hopkins University)
-
Rasul Dent (Inria Paris)
-
Pranav Gupta (Cornell University)
-
Nishat Raihan (George Mason University)
-
Claire Bizon Monroc (Inria Paris)
-
Ruth-Ann Armstrong (University of Southern California)
-
Kenton Murray (Johns Hopkins University)
-
Raj Dabre (Google)
-
Andre Coy (University of the West Indes)
CONTACT
-
Organizers: creolemtsharedtask@gmail.com
-
Shared task community: creole-mt-shared-task@googlegroups.com
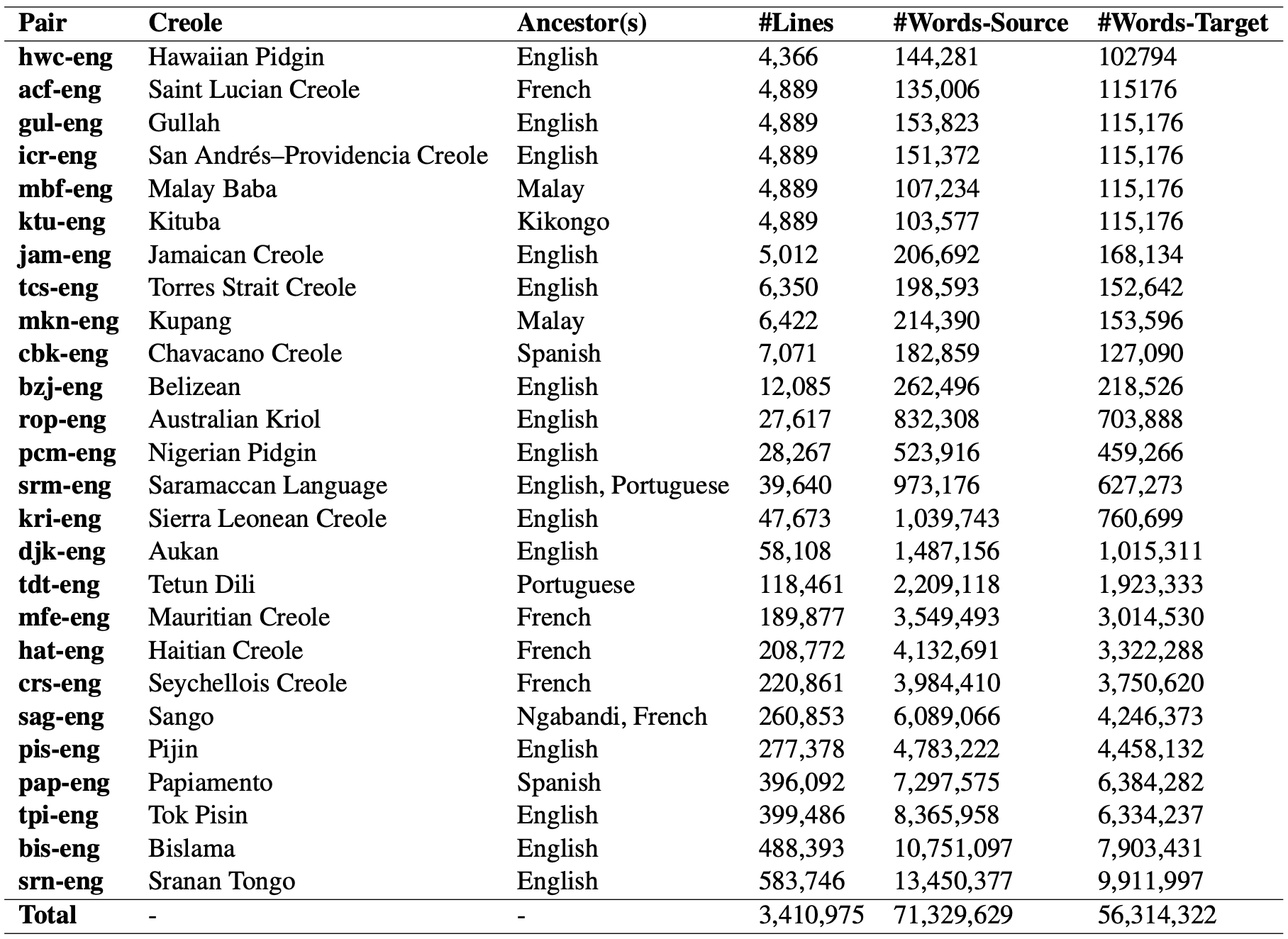
CREOLE LANGUAGES SUPPORTED BY BASELINE MODELS
Here are the languages supported by Kreyòl-MT (from the paper).
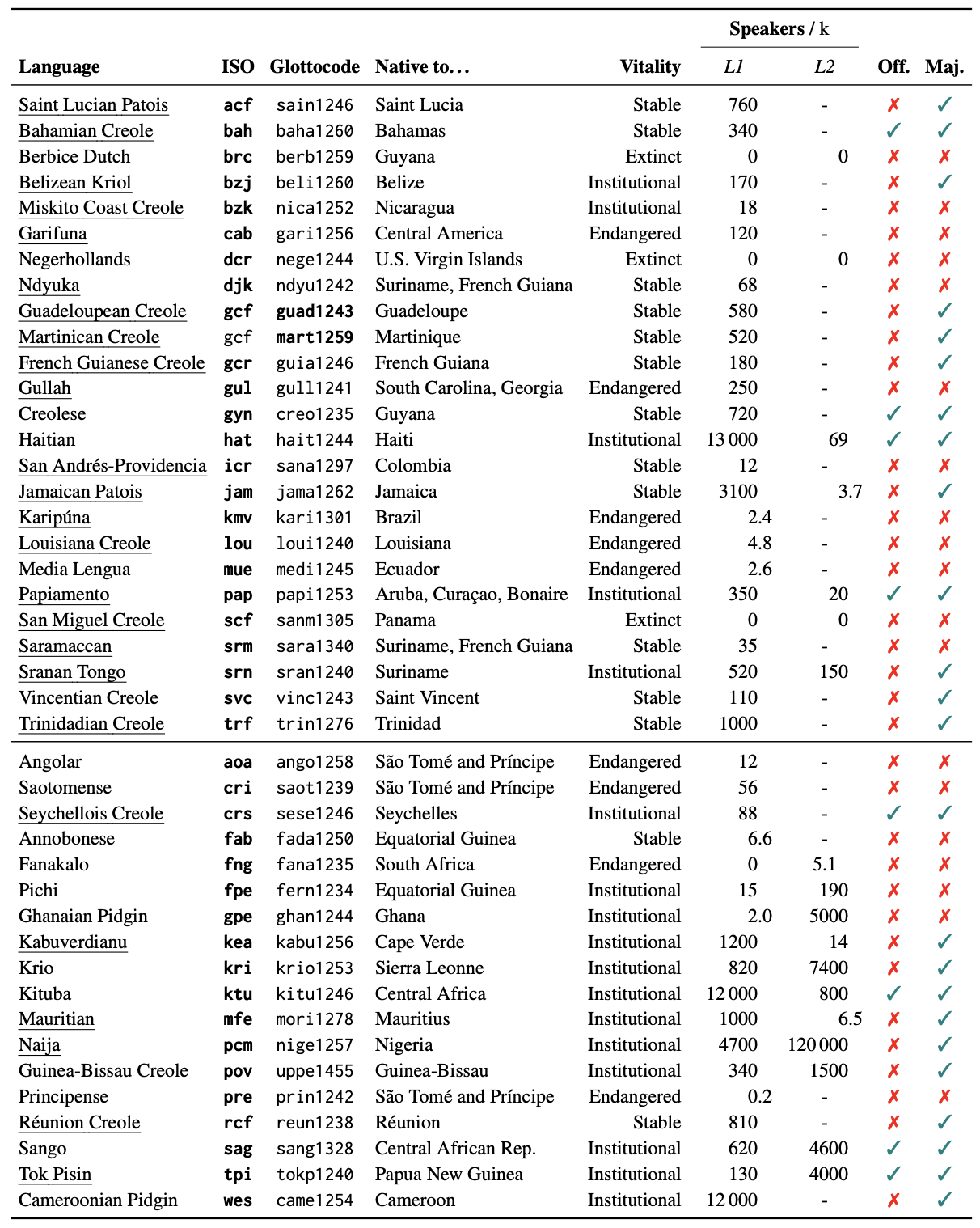
And here are the languages supported by CreoleVal (from the paper).