ANNOUNCEMENTS
- ⚠️ Upon submitting, you should expect a confirmation email. If you don't receive this, please reach out to us directly at vincentwang0229@gmail.com. ⚠️
- You can continue to submit your system outputs to Longyue Wang after DDL (we will mark the difference in report).
- Please email your system outputs to Longyue Wang, before July 27th, 2023 AOE (Go to Section 'Result submissions').
- 2023-07-14 - testing input release (Go to Section 'DATA-Download'). 📚
- 2023-05-02 - pretained models release. 📚
- 2023-05-06 - dataset release. 📚
- 2023-04-14 - website launch. 🌍
IMPORTANT DATES
| Release of Train, Valid and Test Data 📚 | May 6th, 2023 |
| Release of Official Test Data 🚀 | July 14th, 2023 |
| Result submission deadline 🏆 | July 27th, 2023 |
| System description abstract 📝 | July 27th, 2023 |
| System paper submission deadline ❤️ | TBC - September, 2023 |
All deadlines are Anywhere on Earth. Please note that the submission process for system papers follows the paper submission policy outlined by WMT. For further details, please refer to the "Paper Submission Information" section on the WMT homepage.
OVERVIEW
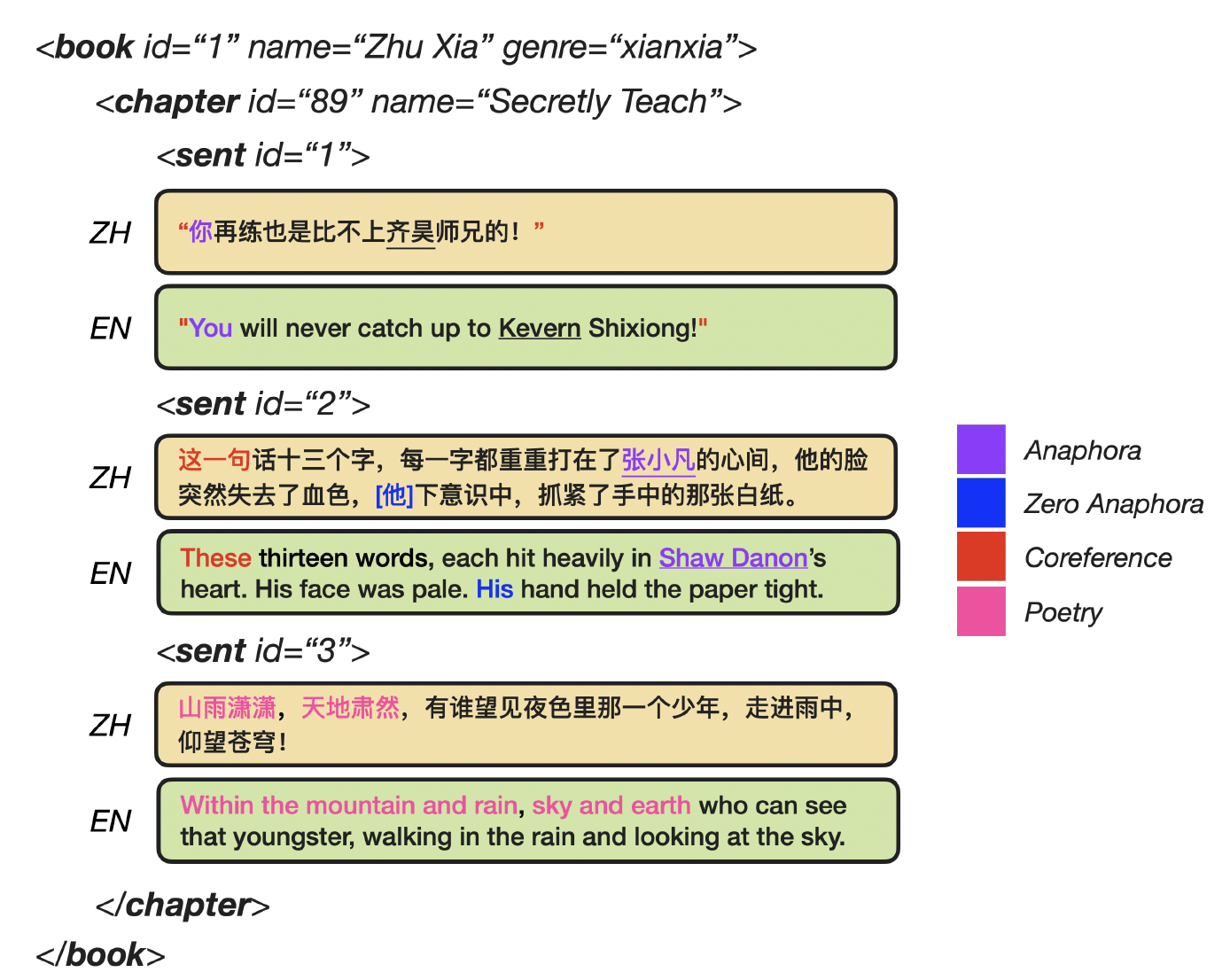
Machine translation (MT) faces significant challenges when dealing with literary texts due to their complex nature, as shown in Figure 1. In general, literary MT is bottlenecked by several factors:
- 😢 Limited Training Data: Most existing document-level datasets are comprised of news articles and technical documents, with limited availability of high-quality, discourse-level parallel data in the literary domain. This scarcity of data makes it difficult to develop systems that can handle the complexities of literary translation.
- 😱 Rich Linguistic Phenomena: Literary texts contain more complex linguistic knowledge than non-literary ones, especially with regard to discourse. To generate a cohesive and coherent output, MT models require an understanding of the intended meaning and structure of the text at the discourse level.
- 😅 Long-Range Contex: Literary works, such as novels, have much longer contexts than texts in other domains, such as news articles. Translation models must acquire the ability to model long-range context in order to learn translation consistency and appropriate lexical choices.
- 😔 Unreliable Evaluation Methods: Evaluating literary translations requires measuring the meaning and structure of the text, as well as the nuances and complexities of the source language. A single automatic evaluation using a single reference is often unreliable. Thus, professional translators with well-defined scoring standards and targeted evaluation methods are considered a complement.
The main goals of the task are to:
- 😊 Encourage research in machine translation for literary texts.
- 🤗 Provide a platform for researchers to evaluate and compare the performance of different machine translation systems on a common dataset.
- 😃 Advance the state of the art in machine translation for literary texts.
TASK DESCRIPTION
The shared task will be the translation of web fiction texts from Chinese to English.
Participants will be provided with two types of training dataset:
- GuoFeng Webnovel Corpus: we release a in-domain, discourse-level and human-translated training dataset (please go to Section "Data").
- General MT Track Parallel Training Data: you can use all parallel training data (e.g. sentence-level and document-level) of the general translation task;
- Simple Set contains unseen chapters in the same web novels as the training data;
- Difficult Set contains chapters in different web novels from the training data.
- In-domain RoBERTa (base) 12 layer encoder, hidden size 768, vocabulary size 21,128, whole word masking. It was originally pretrained on Chinese Wikipedia. We continously train it with Chinese literary texts (84B tokens). (please go to Section "Pretrained Models").
- In-domain mBART (CC25): 12 layer encoder and 12 layer decoder, hidden size 1024, vocabulary size 250,000. It was originally trained with 25 language web corpus. We continously train it with English and Chinese literary texts (114B tokens). (please go to Section "Pretrained Models").
- General-domain Pretrained Models: General MT Track listed pretrained models in all publicly available model sizes: mBART, BERT, RoBERTa, sBERT, LaBSE.
The task has Constrained and Unconstrained Track with different constraints on the training of the models:
- Constrained Tack You may ONLY use the training data specified above; Any basic linguistics tools (taggers, parsers, morphology analyzers, etc.).
- Unconstrained Tack allows the participation with a system trained without any limitations.
DATA
Copyright and Licence
Copyright is a crucial consideration when it comes to releasing literary texts, and we (Tencent AI Lab and China Literature Ltd.) are the rightful copyright owners of the web fictions included in this dataset. We are pleased to make this data available to the research community, subject to certain terms and conditions.
- 🔔 GuoFeng Webnovel Corpus are copyrighted by Tencent AI Lab and China Literature Limited.
- 🚦 After completing the registration process with your institute information, WMT participants or researchers are granted permission to use the dataset solely for non-commercial research purposes and must comply with the principles of fair use (CC-BY 4.0).
- 🔒 Modifying or redistributing the dataset is strictly prohibited. If you plan to make any changes to the dataset, such as adding more annotations, with the intention of publishing it publicly, please contact us first to obtain written consent.
- 🚧 By using this dataset, you agree to the terms and conditions outlined above. We take copyright infringement very seriously and will take legal action against any unauthorized use of our data.
📝 If you use our datasets, please cite the following papers and claim the original download link (http://www2.statmt.org/wmt23/literary-translation-task.html):
- Longyue Wang, Chenyang Lyu, Zefeng Du, Dian Yu, Liting Zhou, Siyou Liu, Yan Gu, Yufeng Ma, Weiyu Chen, Yulin Yuan, Bonnie Webber, Philipp Koehn, Yvette Graham, Andy Way, Shuming Shi, Zhaopeng Tu. Findings of the WMT 2023 Shared Task on Discourse-Level Literary Translation. Proceedings of the Eighth Conference on Machine Translation (WMT). 2023. [bib]
- Longyue Wang, Zefeng Du, DongHuai Liu, Deng Cai, Dian Yu, Haiyun Jiang, Yan Wang, Shuming Shi, Zhaopeng Tu. GuoFeng: A Discourse-aware Evaluation Benchmark for Language Understanding, Translation and Generation. 2023. [bib]
Data Description (GuoFeng Webnovel Corpus)
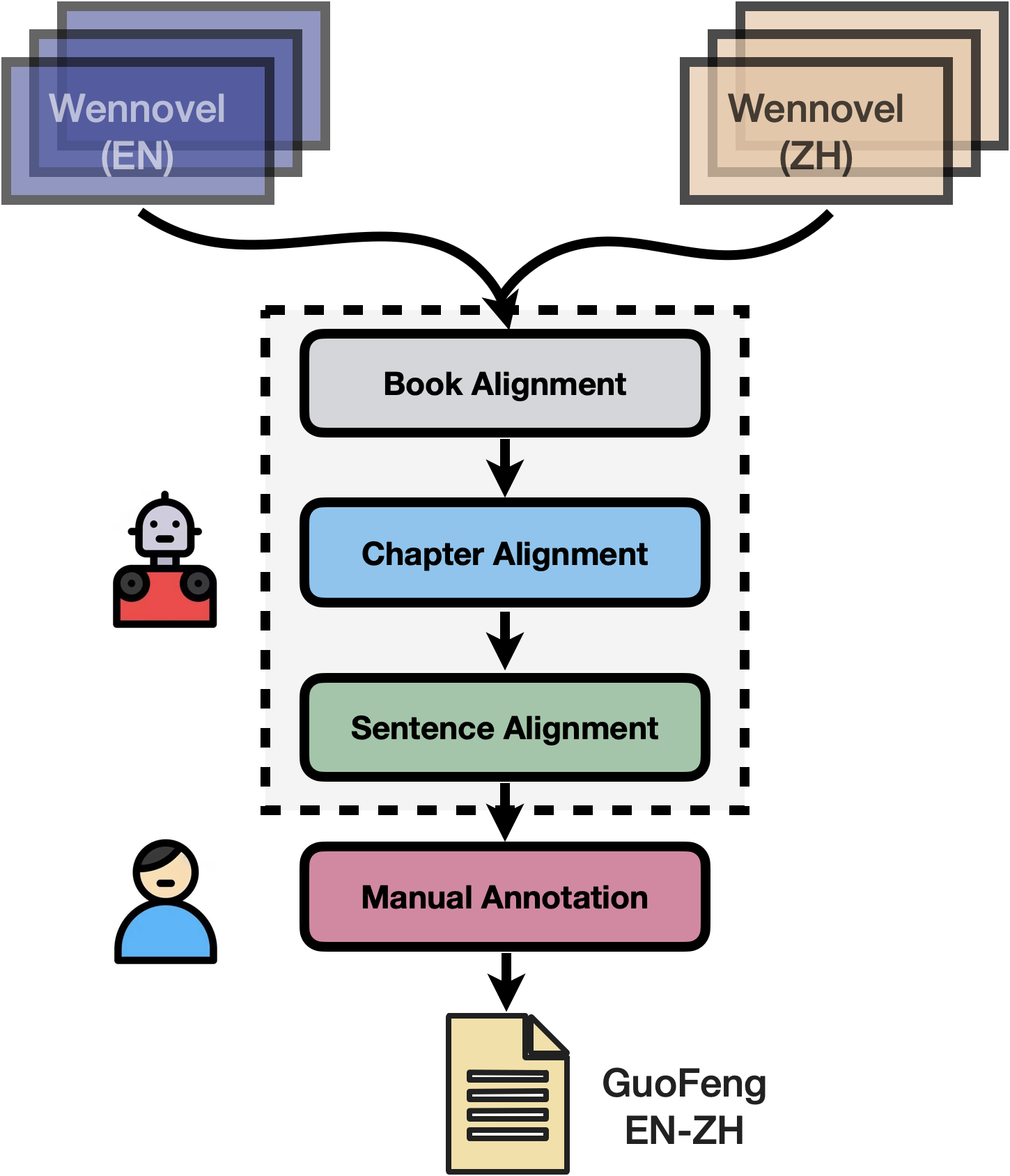
💌 The web novels are originally written in Chinese by novel writers and then translated into English by professional translators. As shown in Figure 2, we processed the data using automatic and manual methods: (1) align Chinese books with its English versions by title information; (2) In each book, align Chinese-English chapters according to Chapter ID numbers; (3) Build a MT-based sentence aligner to genrate parallel sentences; (4) ask human annotates to check and revise the alignment errors.
💡 Note that (1) some sentences may have no aliged translations, because human translators translate novels in a document way; (2) we keep the all document-level information such as continous chapters and sentences.
Download: We release 22,567 continuous chapters from 179 web novels, covering 14 genres such as fantasy science and romance. The data statistics are listed in Table 1.
| # Book | # Chapter | # Sentence | Notes | |
|---|---|---|---|---|
| Train | 179 | 22,567 | 1,939,187 | covering 14 genres |
| Valid 1 | 22 | 22 | 755 | same books with Train |
| Test 1 | 26 | 22 | 697 | same books with Train |
| Valid 2 | 10 | 10 | 853 | different books with Train |
| Test 2 | 12 | 12 | 917 | different books with Train |
| Testing Input | 12 | 239 | 16,742 | different books with Train, super-long documents |
🎈 Testing Input 🎈
Data Format: Taking "train.en" for exaple, the data format is shown as follows: <BOOK id=""> </BOOK> indicates a book boundary, which contains a number of continous chapters with the tag <CHAPTER id=""> </CHAPTER>. The contents are splited into sentences and manually aligned to Chinese sentences in "train.zh".
<BOOK id="100-jdxx">
<CHAPTER id="jdxx_0001">
Chapter 1 Make Your Choice, Youth
"Implode reality, pulverize thy spirit. By banishing this world, comply with the blood pact, I will summon forth thee, O' young Demon King!"
At a park during sunset, a childlike, handsome youth placed his left hand on his chest, while his right hand was stretched out with his fingers wide open, as though he was about to release something amazing from his palm. He looked serious and solemn.
... ...
</CHAPTER>
<CHAPTER id="jdxx_0002">
....
</CHAPTER>
</BOOK>
PRETRAINED MODELS
| Version | Layer | Hidden Size | Vocabulary Size | Continuous Train | |
|---|---|---|---|---|---|
| RoBERTa | base | 12 enc | 768 | 21,128 | Chinese literary texts (84B tokens) |
| mBART | CC25 | 12 enc + 12 dec | 1,024 | 250,000 | English and Chinese literary texts (114B tokens) |
EVALUATION METHODS
👨👩👧👦 Human Evaluation: Besides, we provide professional translators to assess the translations based on more subjective criteria, such as the preservation of literary style and the overall coherence and cohesiveness of the translated texts. Based on our experience with this project, we designed a fine-grained error typology and marking criteria for literary MT.
RESULTS SUBMISSION
- Participants can submit either constrained or unconstrained systems with flags, and we will distinguish their submissions.
- Each team can submit at most 3 MT outputs per language pair direction, one primary and up to two contrastive.
- Submissions will be done by sending us an email to Longyue Wang.
- The requirements of submission format are (1) Keep 12 output files that are identical to the testing input files. (2) In the output files, ensure that each line is aligned with the corresponding input line. If a particular input line is blank, the corresponding output line should also be blank..
Submission Email Format:
Subject: WMT2023 Literary Translation Submission (Team Name)
Basic Information: your team name, affiliations, team member names.
System Flag: constrained or unconstrained.
System Description: main techniques and toolkits used in your three submission systems.
Attachment: File names associated with testing input IDs (primary-1.out, primary-2.out, ..., contrastive1-1.out, ..., contrastive2-12.out)
COMMITTEE
Organization Team
- Longyue Wang (vincentwang0229@gmail.com) (Tencent AI Lab)
- Zhaopeng Tu (Tencent AI Lab)
- Dian Yu (Tencent AI Lab)
- Shuming Shi (Tencent AI Lab)
- Yan Gu (China Literature Limited)
- Yufeng Ma (China Literature Limited)
- Weiyu Chen (China Literature Limited)
Evaluation Team
- Liting Zhou (Dublin City University)
- Chenyang Lyu (Dublin City University)
- Siyou Liu (Macao Polytechnic University)
- Zefeng Du (University of Macau)
Advisory Committee
- Yulin Yuan (University of Macau)
- Bonnie Webber (University of Edinburgh)
- Philipp Koehn (Johns Hopkins University)
- Andy Way (Dublin City University)
- Yvette Graham (Trinity College Dublin)
Contact
If you have any further questions or suggestions, please do not hesitate to guofeng-ai googlegroup or send an email to Longyue Wang.